2. Каскадное соединение в качестве модели неразветвлённого голосового тракта |
Предыдущая Содержание Следующая |
|
|
Поскольку достоинства каскадных синтезаторов применяются специально для моделирования речевого тракта в течение не-назальных сонорных, обсуждение в данном разделе ограничено каскадным моделированием неразветвленного голосового тракта, возбуждаемого голосовой щелью. Другие факторы, которые влияют на синтетический спектр речи, рассматриваются в последующих разделах.
В настоящее время хорошо установлено [10], что если голосовой тракт рассматривается как неоднородная неразветвлённая акустическая труба, возбуждаемая исключительно на конце голосовой щелью, и излучает звук только со стороны рта, и если требуется такой диапазон частот, что передача звука в трубе может полностью рассматриваться в виде плоских волн, то передаточная функция имеет вид
то есть она содержит только полюсы, соответствующие различным резонансным режимам модели голосового тракта. Среднее расстояние между полюсами в частотной области задаётся
где d является расстоянием между полюсами, L является длиной вокального тракта и c - скорость звука в тракте. Для голоса типичного взрослого мужчины это среднее расстояние составляет около 1 кГц. Хотя число полюсов бесконечно, существует несколько причин, почему резонансы выше 5 кГц имеют очень малое прямое влияние на выходной сигнал:
(i) затухание этих высших резонансов очень велико, в основном потому, что потери на излучение во рту гораздо больше для длин волн меньших, чем размер ротового отверстия; (ii) спектральная плотность мощности гортанного источника звука выше 5 кГц очень мала; (iii) и чувствительность, и разборчивость по частоте человеческого слухового восприятия выше 5 кГц значительно сокращается.
Вышеприведённые причины (i) и (ii) приводят к очень небольшой голосовой энергии, производимой выше 5 кГц, а причина (iii) придаёт спектральной структуре любого сигнала в этой области очень малое значение.
Однако, бесконечное число высокочастотных полюсов в уравнении (1) имеет весьма значительный кумулятивный эффект в области нескольких нижайших формант и в аналоговых каскадных синтезаторах обычно приближаются к этой цели используя лишь небольшое число явных резонаторов (обычно 4 или 5), а также используя схему "коррекции высшего полюса" [11], чтобы дать этим явным формантам необходимое усиление в области высокой частоты, которое обычно происходит в человеческой речи. Для этого обычно выбирают коррекцию верхнего полюса, который подходит для равномерной трубы той же длины, что и речевой тракт (например, для идеального нейтрального гласного). Если для модели 17 см голосового тракта используется пять явных формант, эта коррекция высшего полюса равна амплитуде отклика бесконечного множества резонаторов, частоты которых отстоят на 1 кГц друг от друга, начиная с 5.5 кГц. На высших частотах полосы речи величина этой коррекции очень велика (около 57 дБ на 5 кГц). В дискретных каскадных синтезаторах происходящее преобразование в z-области в дискретных фильтрах обеспечивает бесконечный ряд полюсов в s плоскости, так что необходимо только обеспечить явные полюса в пространстве справа до половины частоты дискретизации (Fs/2) для достижения автоматической коррекции высшего полюса [4]. Существует, однако, небольшое теоретическое различие между аналоговым и дискретным методами, обеспечивающими получение характеристик коррекции высшего полюса, что может быть заметно, если пользователь синтезатора имеет контроль частот всех явных полюсов в передаточной функции. В дискретном случае любое движение частоты высшего из этих полюсов к или от Fs/2 имеет соответствующий эффект, отображаемый выше Fs/2, и, таким образом, приводит к изменению эффективной коррекции высшего полюса, вызывая соответственно подъём или падение уровня вблизи Fs/2. Очевидно, что для такого изменения не может быть никакого теоретического обоснования. Существующая структура полюсов, порождаемая выше Fs/2, связана с тем, что в эквивалентной модели акустической трубы дискретной всеполюсной сети [12] распространение плоской волны подразумевается на всех частотах, и эта труба имеет функцию области поперечного сечения (Рис. 1). Ни одно из этих предположений не является реалистичным; более того, при наиболее часто используемой частоте дискретизации 10 кГц в этой трубе есть только 10 секций. Рис. 2 показывает некоторые примеры частотной характеристики 5-ти формантного аналогового и дискретного синтезатора, использующего частоту сэмплирования 10 кГц, для иллюстрации различий, которые могут возникнуть между этими двумя формами коррекции высшего полюса для двух возможных конфигураций высших формант. На Рис. 2b видно, что на 5 кГц отклик дискретного на несколько децибел ниже характеристики аналогового, в то время как на Рис. 2d верно обратное. Конечно, при желании возможно близко приблизиться к 5-ти формантной аналоговой характеристике с помощью дискретной реализации, работающей на более высокой частоте дискретизации, например, 20 кГц, и имеющей форманты выше, чем F5, расположенные на 5.5 кГц, 6.5 кГц и так далее.
 Рис. 1. Типичная функция поперечного сечения акустической трубы, применяемая в каскадном дискретном синтезаторе.
 Рис. 2. (a) и (c) Типичные характеристики гласной для каскадного аналогового синтезатора с коррекцией высшего полюса, использующего разные частоты для F4 и F5;
Хотя Рис. 2 иллюстрирует возможные большие различия между аналоговой и дискретной коррекцией высшего полюса, нет никаких причин, почему каждый из них должен близко приблизиться к влиянию высших полюсов реального речевого тракта, особенно в экстремальных артикуляционных конфигурациях. Не учитываются ни фактические позиции частот этих высших полюсов, ни возможно большие изменения в их затухании. Разница в длине голосового тракта между артикуляциями с округлёнными и открытыми губами обычно также игнорируется. Сочетание всех этих эффектов может легко привести к ошибкам во много децибел в области около 3 - 4 кГц, а для тех гласных, у которых уровень в этой области обычно высок, последствия этого были бы восприняты как очень значительные.
Существует ещё одна причина неопределенности моделирования высокочастотных компонентов гласных. Форма сечения голосового тракта может быть довольно сложной во многих местах, с сечениями не менее 6 см в наиболее широкой части для некоторых гласных. Половина длины звуковой волны в голосовом тракте на 3 кГц составляет всего около 5 - 6 см, и, таким образом, следует ожидать, что отклонение от распространения плоской волны в точках, где сечение голосового тракта становится большим, будет заметно влиять на отклик на 3 кГц и выше. К сожалению, как только отклонение от распространения плоской волны должно быть принято во внимание, отклик тракта становится чрезвычайно трудно анализировать теоретически. Однако, некоторое представление вероятного порядка величины эффекта было продемонстрировано путём измерения в чрезвычайно простой акустической модели голосового тракта регулируемых размеров [13]. В этой модели воздушный путь имеет постоянную толщину 1.2 см. Общая длина зафиксирована на 17 см, а площадь поперечного сечения регулируется отдельно в двух 8.5 см секциях за счёт изменения расстояния до верхней и нижней стенки, как показано на Рис. 3. Толщина настолько мала, что модель можно считать 2-мерной по крайней мере до 8 кГц. Модель возбуждается разрядником, а излучаемый отклик был проанализирован спектрально. Рис. 4 показывает отклик для формы, грубо соответствующей гласной [e]. Были использованы два различных набора размеров сечения с соотношением размеров 3:1. Видно, что когда максимальный размер сечения был всего лишь 2 см, в отклике до 8 кГц было в общей сложности восемь формант, как и предсказывалось теорией акустической трубы с плоской волной. Для максимального размера 6 см три нижние форманты были очень похожи на те же для случая 2 см, но выше 3 кГц наблюдались несколько дополнительных резонансных режима, а также редкие глубокие провалы, вызванные антирезонансами.
 Рис. 3. Простая акустическая модель, представляющая простейший голосовой тракт.
 Рис. 4. (a) Выходной спектр модели, показанной на Рис. 3, измеренный с помощью полосы анализа 50 Гц;
Из вышеизложенного видно, что для тех звуков, которые производятся каскадной моделью неразветвлённого голосового тракта, вероятно, будет возможно получить хорошее приближение к отклику голосового тракта до примерно 3 кГц, но что величина моделируемого отклика может существенно отличаться на более высоких частотах. Для слухового восприятия наиболее важные особенности в области 3 - 5 кГц - это уровни в областях спектра, примерно такие же широкие, как критические полосы [14]. Подходящие уровни могут быть достигнуты манипулированием позиций полюсов и большие изменения уровней, получаемых таким образом, хорошо иллюстрируются двумя наборами частот высших формант, использованных на Рис. 2. Раздел II.C Клатта [3] сообщает об использовании этого метода создания спектральных уровней выше 3 кГц, но нет очевидных причин, почему частоты полюсов должны быть такими же, как резонансные режимы реального речевого тракта. Тот факт, что предположение о плоской волне не является действительным выше 3 кГц для реалистичных размеров голосового тракта означает, что отклик в этой области будет в общем иметь больше резонансов, чем всеполюсная модель, а также антирезонансы, которые будут влиять на интенсивность сигналов на резонансных частотах. Поскольку этими резонансами двигают артикуляторы, следует ожидать движение сложным путём и антирезонансов, как иллюстрируется спектрограммой типичного естесвенного произношения, показанного на Рис. 5.
 Рис. 5. Спектрограмма натуральной речи, иллюстрирующая сложную резонансную структуру между 3 кГц и 4 кГц.
Критические зоны в этой части спектра шириной порядка 500 Гц, и, таким образом, мелкие детали сигнала в частотной области сами по себе, вероятно, не будут важны для восприятия. Однако, биения между компонентами спектральной картины в критической полосе приведут к сложной огибающей во времени в ответ на каждый импульс голосовой щели. Эта сложность временной структуры может быть субъективно обнаруживаема в некоторых обстоятельствах, но не может быть смоделирована с использованием расстояния между полюсами простого каскадного синтезатора.
|
| Предыдущая Содержание Следующая |
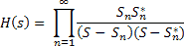 (1)
(1)