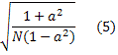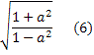4. ПОЛУЧЕНИЕ ОТПЕЧАТКОВ ЗВУКА |
Предыдущая Содержание Следующая |
|
4.1 Основные принципыЗвуковые отпечатки собираются уловить особенности звука, имеющие отношение к восприятию. В то же время получение и поиск отпечатков должно быть быстрым и простым, желательно с небольшой детализацией, чтобы позволить использование в очень востребованных приложениях (например, распознавание в мобильном телефоне). До начала разработки и реализации такой схемы снятия отпечатков должны быть рассмотрены несколько фундаментальных вопросов. Наиболее очевидный вопрос для обсуждения: какие особенности являются наиболее подходящими. Просмотр существующей литературы показывает, что набор соответствующих особенностей можно разделить на два класса: класс семантических особенностей и класс не-семантических особенностей. Типичными элементами первого класса являются жанр, число ударов в минуту и настроение. Эти типы особенностей обычно имеют прямое толкование и на самом деле используются для классификации музыки, создания плей-листов и многого другого. Второй класс состоит из особенностей, которые имеют более математический характер и трудны для "чтения" человеком непосредственно из музыки. Типичным элементом в этом классе является AudioFlatness, который предлагается в MPEG-7 в качестве инструмента описания звука [2]. Для работы, описанной в этой статье, мы по ряду причин явно выбрали работу с не-семантическими особенностями:
1.Семантические особенности не всегда имеют чёткий и однозначный смысл. То есть личное мнение сильно отличается для таких классификаций. Кроме того, семантика может на самом деле изменяться с течением времени. Например, музыку, которая была классифицирована как хард-рок 25 лет назад, можно рассматривать сегодня как приятную музыку. Это делает математический анализ затруднительным. 2.Семантические особенности являются в целом более сложно вычислимыми, чем не-семантические особенности. 3.Семантические особенности не универсальны. Например, число ударов в минуту обычно не применяется к классической музыке.
Вторым вопросом, который предстоит рассмотреть, является представление отпечатков. Очевидным кандидатом является представление в виде вектора вещественных чисел, где каждый компонент выражает вес некоторой основной особенности восприятия. Второй вариант - оставаться ближе по духу к криптографическим хэш-функциям и представить цифровые отпечатки как битовые строки. По причинам сокращения сложности поиска мы решили в этой работе выбрать второй вариант. Первый вариант предполагал бы измерение сходства с помощью суммирований/вычитаний реальных чисел и, в зависимости от меры сходства, возможно, даже умножения реальных чисел. Отпечатки, которые основаны на битовых представлениях, можно сравнивать просто считая биты. С учётом ожидаемых сценариев применения мы не ожидаем высокой надёжности для каждого бита в таких бинарных отпечатках. Поэтому в отличие от криптографических хэшей, которые обычно имеют по крайней мере несколько сотен бит, мы позволим отпечатки, которые имеют несколько тысяч бит. Отпечатки, содержащие большое количество битов, позволяют надёжную идентификацию, даже если процент несовпадающих битов является относительно высоким.
Последний вопрос относится к степени детализации отпечатков. В приложениях, которые мы предусматриваем, нет никакой гарантии, что аудио файлы, которые должны быть определены, являются полными. Например, при мониторинге эфир любой интервал от 5 секунд является единицей музыки, которая имеет коммерческую ценность, и поэтому, возможно, должен быть идентифицирован и опознан. Кроме того, в приложениях безопасности, таких как фильтрация файлов в обменной сети, никто не хотел бы, чтобы исключение первых нескольких секунд звукового файла препятствовало идентификации. В данной работе мы поэтому адаптировали контроль потоков отпечатков путём создания суб-отпечатков для достаточно малых базовых интервалов (названных кадрами). Эти суб-отпечатки не могут быть достаточно большими, чтобы непосредственно идентифицировать кадры, но более длительный интервал, содержащий достаточно много кадров, позволит надёжную и достоверную идентификацию. 4.2 Алгоритм полученияБольшинство алгоритмов получения отпечатков основаны на следующем подходе. Сначала звуковой сигнал разделяется на кадры. Для каждого кадра вычисляется набор характеристик. Предпочтительно характеристики выбраны так, что они инвариантны (по крайней мере в определённой степени) к искажениям сигнала. Предложенными характеристиками являются хорошо известные характеристики звука, такие как коэффициенты Фурье [4], коэффициенты косинусного преобразования Фурье (Mel Frequency Cepstral Coefficients, MFFC) [18], неравномерность спектра (spectral flatness) [2], чёткость звучания (sharpness) [2], коэффициенты линейное кодирования с предсказанием (Linear Predictive Coding, LPC) [2] и другие. Также используются производные величины параметров звука, такие как производные, средний уровень и дисперсия. Вообще, полученные характеристики переходят в более компактное представление, используя алгоритмы классификации, такие как скрытые Марковские модели [3] или квантование [5]. Компактное представление одного кадра будем называть суб-отпечатком. Полная процедура получения отпечатков преобразует поток звука в поток суб-отпечатков. Один суб-отпечаток обычно не содержит достаточных данных для идентификации аудио клипа. Основная единица, которая содержит достаточно данных для идентификации аудио клипа (и, следовательно, определяет детализацию), будет называться блок отпечатков.
Предложенная схема получения отпечатков базируется на этом подходе обработки потока. Она создаёт 32-х разрядной суб-отпечаток для каждого интервала в 11.6 миллисекунд. Блок отпечатков состоит из 256 последовательных суб-отпечатков, что соответствует детализации всего лишь в 3 секунды. Обзор схемы показан на Рисунке 1. Аудио сигнал сначала разделяется на перекрывающиеся кадры. Перекрывающиеся кадры имеют длительность 0.37 секунды и взвешиваются окном Ханна с фактором перекрытия 31/32 (так в оригинале, правильнее, видимо, Перекрывающиеся кадры имеют длительность 0.37 секунды с фактором перекрытия 31/32 и взвешиваются окном Ханна). Эта стратегия приводит к получению одного суб-отпечатка каждые 11.6 мс. В худшем случае границы кадра, используемые во время идентификации, смещены на 5.8 миллисекунд относительно границ, использованных в базе данных предварительно вычисленных отпечатков. Большое перекрытия гарантирует, что даже в этом худшем случае суб-отпечатки аудиоклипа, который должен быть идентифицирован, всё ещё очень похожи на суб-отпечатки того же клипа в базе данных. Из-за большого перекрытия последовательные суб-отпечатки имеют большое сходство и медленно меняются во времени. На Рисунке 2a показан пример получения блока отпечатков и их медленно меняющийся характер вдоль оси времени.
 Рисунок 1. Обзор схемы получения отпечатка.
Наиболее важные воспринимаемые характеристики звука живут в частотной области. Поэтому спектральное представление вычисляется путём выполнения преобразования Фурье на каждом кадре. Из-за чувствительности преобразования Фурье к фазе для разных границ кадра и того факта, что человеческая слуховая система (Human Auditory System, HAS) является относительно нечувствительной к фазе, сохраняется только абсолютная величина спектра, то есть спектральная плотность мощности.
Для того чтобы получить 32-х разрядное значение суб-отпечатка для каждого кадра, выбраны 33 неперекрывающихся диапазона частот. Эти полосы лежат в диапазоне от 300 Гц до 2000 Гц (наиболее важные области спектра для HAS) и имеют логарифмический интервал. Логарифмической интервал выбран потому, что известно, что HAS работает примерно на логарифмических полосах (так называемая шкала Барка, Bark scale). Экспериментально было проверено, что знак разности энергий (одновременно по осям времени и частоты) является свойством, которое очень устойчиво ко многим видам обработки. Если мы обозначим энергию диапазона m кадра n как E(n,m) и m-ый бит суб-отпечатка фрейма n как F(n,m), то биты суб-отпечатка формально определяются как (смотрите также серый блок на Рисунке 1, где T - элемент задержки):
Рисунок 2 показывает пример из 256 последовательных 32-х разрядных суб-отпечатков (то есть блок отпечатков), полученный с помощью вышеописанной схемы из небольшого фрагмента из "O Fortuna" Carl Orff. Бит '1' соответствует белому пикселю, а бит '0' - чёрному пикселю. Рисунки 2a и 2b показывают блок отпечатков из оригинального компакт-диска и сжатой в MP3 (32Kbps) версии того же отрывка, соответственно. В идеале эти две картинки должны быть идентичны, но из-за сжатия некоторые из битов получены неправильно. Эти ошибочные биты, которые используются в качестве меры сходства для нашей схемы отпечатков, показаны чёрным на Рисунке 2c.
 Блок отпечатка оригинального музыкального клипа, (b) блок отпечатка скомпрессированной версии, (c) различие между a и b, показывающее ошибочные биты чёрным (BER=0.078).") Рисунок 2. (a) Блок отпечатка оригинального музыкального клипа,
Вычислительные ресурсы, необходимые для предложенного алгоритма являются ограниченными. Так как алгоритм учитывает только частоты ниже 2 кГц, получаемый звук сначала ресэмплируется до более низкой частоты для получения монофонического аудио потока с частотой дискретизации 5 кГц. Суб-отпечатки разработаны таким образом, что они являются стойкими к искажениям сигнала. Поэтому для понижающего частоту дискретизации ресэмплирования могут быть использованы очень простые фильтры, не приводящие к какому-либо снижению производительности. В настоящее время используются КИХ фильтры 16-го порядка. Наиболее вычислительно ресурсоёмкой операцией является преобразование Фурье каждого аудио кадра. В звуковом сигнале с пониженной частотой дискретизации фрейм имеет длину в 2048 сэмплов. Если преобразование Фурье реализовано в виде БПФ для реальных числе с фиксированной точкой, алгоритм получения отпечатков показывает эффективную работу на портативных устройствах, таких как КПК или мобильный телефон. 4.3 Анализ числа ложных срабатыванийДва 3-х секундных звуковых сигнала объявляются похожими, если расстояние Хэмминга (то есть количество ошибочных битов) между двумя полученными от них блоками отпечатков ниже определённого порога T. Это пороговое значение T непосредственно определяет процент ложных срабатываний Pf, то есть как часто звуковые сигналы объявляются похожими: чем меньше T, тем будет меньше вероятность Pf. С другой стороны, малое значение T будет негативно влиять на ложноотрицательную вероятностей Pn, то есть вероятность того, что два сигнала "равны ", но не идентифицированы как таковые.
Для анализа выбора этого порога T, мы считаем, что процесс получения отпечатков даёт случайные i.i.d (независимо и одинаково распределённые, independent and identically distributed) биты. Число ошибочных битов будет иметь биномиальное распределение (n,p), где n равно числу полученных битов, а p (= 0.5) является вероятностью получения бита '0' или '1'. Так как n (= 8192 = 32 * 256) велико в нашем приложении, биномиальное распределение можно аппроксимировать нормальным распределением со средним
где
Однако, на практике суб-отпечатки имеют высокую корреляцию по оси времени. Эта корреляция связана не только со свойственной звуку корреляции во времени, но и большим перекрытием кадров, используемым при получении отпечатков. Более высокая корреляция означает большее стандартное отклонение, как показывает следующее рассуждение.
Пусть есть симметричный бинарный источник с алфавитом {-1,1}, такой, что вероятность того, что символ xi и символ xi+1 равны, является равной q. Тогда можно легко показать, что
где a= 2*q-1. Если источник Z является исключающим ИЛИ двух таких последовательностей X и Y, то Z является симметричной и
Для больших N стандартное отклонение среднего
Переходя обратно к вышеописанному случаю битовых отпечатков, коэффициент корреляции между последовательными битами отпечатков предполагает увеличение стандартного отклонения для BER на коэффициент
Для определения распределения BER с помощью реальных блоков отпечатков была создана база данных отпечатков из 10,000 песен. После этого был определён BER для 100,000 случайно выбранных пар блоков отпечатков. Измеренное стандартное отклонение полученного в результате распределения BER было 0.0148, примерно в 3 раза выше, чем 0.0055, что можно ожидать от случайных независимо распределённых битов.
Рисунок 3 показывает логарифм функции плотности вероятности (Probability Density Function, PDF) измеренного распределения BER и нормальное распределение со средним 0.5 и стандартным отклонением 0.0148. PDF от BER является хорошо приближенным к нормальному распределению. Для BER-ов ниже 0.45 наблюдаются некоторые выбросы из-за недостаточной статистики. Чтобы учесть большее стандартное отклонение распределения BER, в Формулу (2) внесены изменения путём включения множителя 3.
 Рисунок 3. Сравнение функции плотности вероятности BER, изображённой знаком ‘+’ и нормальное распределение.
Порог для BER, использованный в ходе экспериментов, был 4.4 Экспериментальные результаты надёжностиВ этом подразделе мы покажем экспериментальную надёжность предлагаемой схемы получения отпечатков звука. То есть мы попытаемся ответить на вопрос, действительно ли BER между блоком отпечатков оригинальной и искажённой версией аудио клипа остаётся ниже порога
Мы выбрали четыре коротких отрывка звука (стерео, 44.1 кГц, 16 бит) из песен, которые принадлежат к различным музыкальным жанрам: "O Fortuna" Carl Orff, "Success has made a failure of our home" Sinead o’Connor, "Say what you want" Texas и "A whole lot of Rosie" AC/DC. Все отрывки были подвергнуты следующим искажениям сигнала:
•MP3 кодирование/декодирование со скоростью 128 Кбит/с и 32 кбит/с. •Кодирование/декодирование в Real Media при 20 Кбит/с. •GSM кодирование на полной скорости на канале без ошибок и канале с интерференцией несущей (C/I) на уровне 4 дБ (сравнимо с приёмом GSM в туннеле). •Всепропускающий фильтр с использованием системной функции: H(z)=(0.81z2-1.64z+1)/(z2-1.64z+0.81). •Амплитудная компрессия со следующими степенями сжатия: 8.94:1 для |A| ≥ -28.6 дБ; 1.73:1 для -46.4 dB < |A| < -28.6 дБ; 1:1.61 для |A| ≤ -46.4 dB. •Эквализация, типичный 10-ти полосный эквалайзер со следующими настройками:
•Полосовой фильтр с использованием фильтра Баттерворта второго порядка с частотами среза 100 Гц и 6000 Гц. •Изменение времени звучания +4% и -4%. Изменялся только темп, тон не изменялся. •Линейное изменение скорости +1%, -1%, +4% и -4%. Изменялись и тон, и темп. •Добавленный шум с помощью равномерного белого шума с максимальной амплитудой из 512-ти шагов квантования. •Изменение частоты дискретизации, последовательное преобразование вниз и вверх на частоте 22.05 кГц и 44.10 кГц, соответственно. •Цифроаналоговое и аналогоцифровое преобразование с использованием коммерческого аналогового магнитофона.
После этого между блоками отпечатков оригинальной версии и всеми искажёнными версиями для каждого аудио клипа были определены BER-ы. Полученные в результате BER-ы приведены в Таблице 1. Почти все результирующие частоты ошибочных битов значительно ниже порога в 0.35, даже для GSM кодирования (напомним, что кодек GSM оптимизирован для передачи речи, а не для любого звука.). Единственным искажением, приводящим к BER выше порога, является большое линейное изменение скорости. Изменение линейной скорости более, чем на +2.5% или -2.5% процента, обычно приводит к частоте ошибочных битов большей, чем 0.35. Это связано с неточным выравниванием кадров (временные смещения) и масштабированием спектра (смещениями частот). Соответствующее предварительное масштабирование (например, путём перебора) может решить эту проблему.
Таблица 1. BER для разного вида искажений сигнала.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Предыдущая Содержание Следующая |